最有趣的前端旁路攻擊:XSLeaks(下)
從上一篇的最後一段中可以看出一點,那就是當 XSLeaks 跟搜尋這兩件事情結合在一起時,就能夠創造出更大的影響力,而這種攻擊方式又有個名稱叫做 XS-Search。
之所以影響力更大,是因為一般來說搜尋結果應該是私密的,一旦搜尋結果可以利用一些手段被推測出來,就可以使得攻擊者透過搜尋功能去取得機密資訊。那有哪些手段可以利用呢?
除了上一篇講過的幾個方式之外,這篇會講到一個更常用的方式:Cache probing。
Cache probing
快取(Cache)機制在電腦科學的世界中隨處可見,以發出 request 來說,你可以在 JavaScript 自己就先做一層 快取,已經重複的 request 就不再發送,而瀏覽器本身也會按照著 HTTP 的規格,根據 response header 實作快取機制,等到了真的要發送 request 的時候,DNS 也有快取!
瀏覽器有 DNS 的快取,作業系統也有一個,DNS server 也會有自己的快取,真的是到處都可以看到快取的存在,甚至連 CPU 也有 L1、L2 諸如此類的快取機制,以空間換取時間,加快執行速度。
如果你還記得的話,之前提過的 CPU 漏洞 Spectre 與 Meltdown 就與快取有關,其實跟這篇要講的 cache probing 是差不多意思。
顧名思義,這個手法就是利用一個東西是否在快取中來回推原本的資訊。
舉例來說,假設一個網站如果有登入的話,就會顯示歡迎頁面,上面有著一張 welcome.png,沒登入的話就看不到,會導回到登入頁面。而這張圖片顯示以後,就會存在瀏覽器的快取當中。
由於在快取中的圖片載入速度會比較快,所以我們只要試著開啟頁面之後,去偵測載入 welcome.png 的時間,就能知道圖片是否在快取中,進而得知使用者有沒有登入。
直接來看一個過往案例比較快,這是 2020 年 Securitum 在對波蘭的 App ProteGo Safe 做滲透測試時發現的漏洞:Leaking COVID risk group via XS-Leaks。
在疫情嚴重的時候,許多政府都做出了自己的 App 或是網站,用來統一回報身體狀況等等,而波蘭也不例外,政府推出了 ProteGo Safe 的網站,讓人民可以在這上面回報狀況或是查看最新資訊等等。
而根據回報狀況的問卷,會出現四種結果:
- High
- Medium
- Low
- Very low
同時,根據結果的不同,頁面上也會搭配不同的圖片(就稱之為 high.png 與 medium.png 這樣以此類推),例如說最低風險就是一個你很安全的圖示之類的。
而作者就根據了這一點,從載入圖片的時間去偵測出使用者目前回報的身體狀況。如果載入 high.png 的時間最快,就代表使用者目前的狀況是 high,用來偵測的程式碼如下:
<img src="https://example.com/high.png">
<img src="https://example.com/medium.png">
<img src="https://example.com/low.png">
<img src="https://example.com/very_low.png">
而每一張圖片載入的時間則是可以用 performance.getEntries() 取得,就能得知哪一張載入最快。
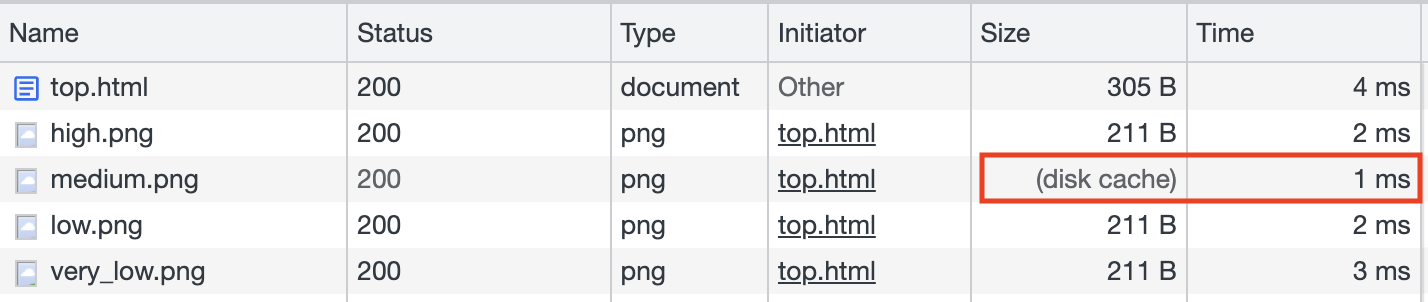
不過有個小問題,那就是這招只能使用一次,因為你打開這網站一次之後,四張圖片都會載入了,下次再測的時候四張都在快取裡,速度都很快。所以,我們必須想個辦法使用者把快取清掉。
當瀏覽器收到的 response 狀態碼是錯誤(4xx 與 5xx)的時候,就會把快取清掉,那我們要怎麼讓 https://example.com/high.png 的回應是錯誤呢?
這邊作者用了一個很聰明的技巧,因為這網站是放在 Cloudflare 上面而且有打開 WAF 功能,因此會自動阻擋一些 payload。比如說 https://example.com/high.png?/etc/passwd 這個 URL 就會因為上面有可疑的 /etc/passwd 而被擋下來,回傳 403 狀態碼。
因此作者最後是在頁面上加入 ?etc/passwd,然後使用:
fetch(url, {
cache: 'reload',
mode: 'no-cors',
referrerPolicy: 'unsafe-url'
})
如此一來,送出的圖片就會有 referrer header,而且裡面的內容含有 /etc/passwd,伺服器就會擋下來,回傳錯誤,就把快取清掉了。
從這個想法去做延伸,假設有一個網站可以讓我們回報自己是否確診,然後也是一樣會根據結果的不同顯示不同圖片,那就可以利用相同的技巧,靠著 XSLeaks 去偵測出現在打開網站的人有沒有確診,洩露出個人隱私。
Cache probing 加 error event,蹦出新滋味
雖然說根據時間來確定一個資源是否在快取中,絕對是個有效的方法,但有時候會受到網路的不確定性影響,例如說網路整體超級快的話,搞不好測出來每一個資源都是 1ms 跟 2ms,就比較難判斷出哪一個是快取的資源。
因此,有另外一種攻擊手法是結合之前講過的用 <img> 來偵測圖片是否載入的方法,再搭配上 cache probing,不用靠時間,而是靠 error event 來判斷是不是在快取中。
假設有一個 https://app.huli.tw/search?q=abc 的頁面,會根據搜尋結果呈現不同畫面,如果有搜尋到東西,就會出現 https://app.huli.tw/found.png,沒搜尋到的話就不會有這張圖片。
首先,第一步一樣要快取清掉,這一步也有很多種方法可以選擇,有一種就跟之前講 cookie bomb 的時候一樣,靠著 request 太大來強制伺服器回傳錯誤,就可以讓瀏覽器清掉快取:
// 程式碼改寫自 https://github.com/xsleaks/xsleaks/wiki/Browser-Side-Channels#cache-and-error-events
let url = 'https://app.huli.tw/found.png';
// 這行可以在 URL 後面加上一堆逗號,送出去的 request 的 referrer 就會太大
history.replaceState(1,1,Array(16e3));
// 發出 request
await fetch(url, {cache: 'reload', mode: 'no-cors'});
第二步則是載入目標網站 https://app.huli.tw/search?q=abc,此時會根據搜尋結果呈現畫面,如同前面所說的,如果有搜尋到東西,那 https://app.huli.tw/found.png 就會出現並且被寫進瀏覽器的快取。
最後一步則是把網址弄得很長以後,再度載入圖片:
// 程式碼改寫自 https://github.com/xsleaks/xsleaks/wiki/Browser-Side-Channels#cache-and-error-events
let url = 'https://app.huli.tw/found.png';
history.replaceState(1,1,Array(16e3));
let img = new Image();
img.src = url;
try {
await new Promise((r, e)=>{img.onerror=e;img.onload=r;});
alert('Resource was cached'); // Otherwise it would have errored out
} catch(e) {
alert('Resource was not cached'); // Otherwise it would have loaded
}
如果圖片沒有在快取中,那瀏覽器就會發 request 去拿,這時候就會碰到跟第一步一樣的狀況,因為 header 太長所以伺服器回傳錯誤,觸發 onerror 事件。
反之,如果在快取中的話,瀏覽器就會直接用快取中的圖片,根本不會發 request,載入快取中的圖片後就會觸發 onload 事件。
如此一來,我們就可以撇開時間這個不安定因素,用快取加上 error 事件來做 XSLeaks。
實際的 Google XS-Search 案例
讓我們來看一個實際運用到這個技巧的案例。
2019 年的時候,terjanq 在 Google 的各項產品中找到了 XS-Search 的漏洞,寫了一篇 Massive XS-Search over multiple Google products,技術細節則是在:Mass XS-Search using Cache Attack,受影響的產品包括:
- My Activity
- Gmail
- Google Search
- Google Books
- Google Bookmarks
- Google Keep
- Google Contacts
- YouTube
透過這些 XS-Search 的攻擊手法,攻擊者可以拿到的資訊包括:
- 搜尋紀錄
- 看過的影片
- email 內容
- 私人筆記
- 存在書籤裡的網頁清單
其實原文還列了很多,但我這邊主要列幾個比較嚴重的。
以 Gmail 來說,它提供了一個「進階搜尋」的功能,有點像 Google 搜尋那樣,可以用一些 filter 去指定搜尋的條件。而這個搜尋功能的 URL 也是可以複製貼上的,開啟 URL 就會直接進入到搜尋頁面。
如果搜尋成功的話,就會出現某一個 icon:https://www.gstatic.com/images/icons/material/system/1x/chevron_left_black_20dp.png
此時就可以利用剛剛提過的手法去偵測出某個搜尋的關鍵字是否存在(截圖自 PoC 影片):

由於 email 本來就是一個有著一堆敏感資訊的地方,例如說有些資安做得不好的網站會直接寄送明文密碼給使用者,就可以利用這招慢慢去洩露出密碼。
舉例來說,如果信件格式是這樣:「您的密碼是12345,請小心保管」,那就陸續搜尋:
- 您的密碼是1
- 您的密碼是2
- 您的密碼是3
- ...
以此類推,就可以洩露出密碼的第一個字,洩漏完之後變成搜尋:
- 您的密碼是 11
- 您的密碼是 12
- 您的密碼是 13
- ...
就可以洩露出第二個字,這樣一直試就可以把完整的密碼洩漏出來。
不過,雖然技術上是可行的,但是要執行這個攻擊比較困難。畢竟洩漏需要時間,而且會開啟一個很可疑的新視窗,要怎麼樣讓使用者不會察覺,就要依靠社交工程技巧了。
從 terjanq 這次的實驗中可以看出利用快取的 XSLeaks 可以在很多產品上執行攻擊,是可行的,除了 Google 以外的網站應該也很多可以用類似的手法去洩露資訊,受到影響的網站會很多。
像這種會影響到很多網站,而且不太算是網站本身問題的漏洞,通常都會交給瀏覽器去處理。
Cache partitioning
剛剛的利用方式都建立在一個前提之上,那就是「所有網站的快取都是共用的」,換句話說,如果能夠打破這個前提,這個攻擊方式就無效了。
於是,Chrome 在 2020 年時啟用了一個新的機制:cache partitioning,快取分區。以前的快取都是每個網站共用同一塊,快取的 key 就是 URL,因此才會讓 XSLeaks 有可趁之機,可以透過偵測快取是否存在去洩露資訊。
而快取分區啟用之後,快取的 key 變得不一樣了,從一個 URL 變成一個 tuple,由底下三個值組成:
- top-level site
- current-frame site
- resource URL
以前面舉過的攻擊的例子來說,假設在 https://app.huli.tw/search?q=abc 載入圖片 https://app.huli.tw/found.png,快取的 key 就是:
而若是從另外一個 https://localhost:5555/exploit.html 的頁面載入圖片 https://app.huli.tw/found.png,快取的 key 就是:
- http://localhost:5555
- http://localhost:5555
- https://app.huli.tw/found.png
在沒有快取分區以前,cache 的 key 就只有第三個,因此這兩個狀況下會共用到同一個快取。而有了快取分區之後,要三個值都一樣,才會存取同一塊快取,而這兩個狀況很明顯是不同的 key,所以會用不同的快取。
因爲用到的快取不同,所以攻擊者就無法從其他頁面執行 cache probing 攻擊,偵測快取是否存在。
而這個快取分區的實作其實對於正常的網站也有一些影響,其中一個例子是共用的 CDN。有些網站例如說 cdnjs,免費 host 了很多 JavaScript 的函式庫,讓網站可以輕鬆載入:
<script src="https://cdnjs.cloudflare.com/ajax/libs/jquery/3.5.1/jquery.min.js" integrity="sha512-bLT0Qm9VnAYZDflyKcBaQ2gg0hSYNQrJ8RilYldYQ1FxQYoCLtUjuuRuZo+fjqhx/qtq/1itJ0C2ejDxltZVFg==" crossorigin="anonymous"></script>
而它原本主打的點之一是載入速度較快,為什麼較快呢,因為可以利用快取。假設很多網站都用了 cdn.js 的服務,你在 A 網站上面載入過了這份檔案,在 B 網站上面就不會再載入一次。
但是快取分區出來以後,就沒辦法這樣了,因為 A 網站跟 B 網站會是不同的 key,因此還是要再載入一次。
最後有另外一點想提的,那就是快取分區主要還是看「site」而非「origin」,所以如果你在一個 same-site 的狀況下,那有沒有快取分區都沒差。
舉剛剛的例子來說,如果我們不是從 http://localhost:5555 發起攻擊,而是從 https://test.huli.tw 發起攻擊呢?快取的 key 就是:
跟從 https://app.huli.tw/search?q=abc 載入圖片是一樣的,所以還是可以執行剛剛的 cache probing 攻擊。
除此之外,headless Chrome 還沒有預設開啟快取分區,所以如果是用 puppeteer 搭配 headless 模式去訪問網站的話,也還是都共用同一個快取 key。
更多 XSLeaks
礙於篇幅的限制,我只介紹到了其中幾種 XSLeaks 的方式,事實上還有許多種手法。
除了可以參考 XS-Leaks Wiki 這個知識寶庫以外,在 2021 年時有一篇論文,名為《 XSinator.com: From a Formal Model to the Automatic Evaluation of Cross-Site Leaks in Web Browsers》,運用自動化的方式找出了許多新的 XSLeaks 方法。
並且還有提供一個網站,上面說明了哪些瀏覽器版本會受到影響:https://xsinator.com/
它一共把可以 leak 的東西分成五種:
- Status code
- Redirects
- API usage
- Page Content
- HTTP header
這五種又分別有個別的方式可以達成。
舉例來說,在重新導向這個分類中有一種名為「Max Redirect Leak」的方式,利用了重新導向的最大次數限制,來偵測某個網頁是不是有進行伺服器端的重新導向。
原理是這樣的,在 fetch 的規格中,對於 response 的重新導向是有次數限制的:
If request’s redirect count is 20, then return a network error.
因此,假設我們要測試的對象是 http://target.com/test,我們就先在自己的 server 做一個會重新導向 19 次的 API,最後一次導向到 http://target.com/test。
如果 http://target.com/test 的 response 是重新導向,就會觸發 20 次的上限,拋出 network error;如果不是重新導向,那就沒事。
所以透過 fetch() 的執行是不是會出現錯誤,就可以知道 http://target.com/test 的結果是不是重新導向。
在 xsinator 的網站中還有很多很有趣的 XSLeaks 手法,有興趣的話可以去看一下。
小結
在這篇裡面我們延續著上一篇提過的 XSLeaks,繼續介紹了以快取來作為 leak oracle 的攻擊方法,這在旁路攻擊的世界裡面是很普遍的一件事情。除此之外,也舉了一些真實的例子,讓大家看看將 XSLeaks 運用到真實世界的網站上,通常可以造成哪些影響。例如說 Google 的那個範例,就證明了 XSLeaks 結合搜尋功能,也能創造出比想像中更大的影響力。
XSLeaks 是我自己最喜歡的前端資安主題,如果真的要認真寫的話,應該寫個完整的 30 天都不是問題,因為真的有很多種不同的方式可以使用,而有些攻擊方式更是利用一些比較底層的東西,攻擊難度更高,需要的前備知識也更多。
雖然說 XSLeaks 這種間接的攻擊方式,影響力沒有直接的 XSS 這麼高,但還是滿好玩的。